An overview to different I/O patterns in Python.
Context
As an SRE, performance is one of the most relevant metrics to look for. Especially nowadays when distributed systems are abstracted by numerous APIs.
When we write code to achieve a goal, sometimes we only think about creating a solution to solve the very immediate problem. The problem can be complex and our solution might be just right but, how much toil are you leaving behind? How well does it scale?
Designing software is hard and yet it's cumbersome to predict edge cases or new features. This is why refactoring code is as much important as adding features, although managers tend to think otherwise. Continuous refactoring can give great benefits to your customers.
How much value does a new feature have if it has a poor user experience?
In this article, we'll go through different patterns of solving a problem (for business people: adding a feature) and the design of it will determine your user experience and SLAs.
The goal
For this example, I wanted to choose an I/O bound problem where the operating system is idle most of the time. A great way of showing this problem is by looking at the dining philosophers problem and how the operating system solves it. Andrew Tanenbaum explains it well in his book.

The idea is to make as many HTTP GET requests as we are given. Simple, right?
Synchronously
Let's say that we want to aggregate data from multiple sources and then fiddle with them. We start with a few websites, so we just approach it with a traditional pattern.
import requests
import os
from time import time
def get_url(domain_name):
results = {}
try:
response = requests.get(f"https://www.{domain_name}", timeout=3, allow_redirects=False)
result = response.status_code
except requests.exceptions.ReadTimeout:
result = "timeout"
except requests.exceptions.ConnectionError:
result = "connection error"
except Exception as e:
result = str(e)
results[domain_name] = result
return results
if __name__ == '__main__':
site_chunk = [10, 100, 500, 1000]
top_sites = f'{os.path.dirname(os.path.realpath(__file__))}/top-1m.csv'
endpoints = load_csv(top_sites) # Adds the domain names from CSV to a list.
for n in site_chunk:
start = time()
results = [get_url(endpoint) for endpoint in endpoints[0:n]]
end = time()
print(f"{n} endpoints took {end-start:.2f} seconds")
How well did this perform?
$ python socket_sync.py
10 endpoints took 3.12 seconds
100 endpoints took 41.84 seconds
500 endpoints took 317.75 seconds
1000 endpoints took 642.83 seconds
Multi Processing
The above execution was running in one process and one thread. From the philosopher's perspective mentioned above, only one of them was able to eat while the others were just thinking. So, let's add more processes.
from multiprocessing import Pool
if __name__ == '__main__':
for n in site_chunk:
start = time()
with Pool() as pool:
results = pool.map(get_url, endpoints[0:n])
end = time()
print(f"{n} endpoints took {end-start:.2f} seconds")
# Using 8 processes
$ python socket_multiprocessing.py
10 endpoints took 0.95 seconds
100 endpoints took 8.68 seconds
500 endpoints took 52.82 seconds
1000 endpoints took 86.07 seconds
All right this is better, but it's very expensive for our operating system.
Concurrency
Since threads are part of one process and are more lightweight, let's explore the difference. Python implements Futures
as a pool of threads that will return at some point.
import concurrent.futures
def main(endpoints):
results = []
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = {executor.submit(get_url, endpoint): endpoint for endpoint in endpoints}
for future in concurrent.futures.as_completed(futures):
endpoint = futures[future]
try:
results.append(future.result())
except Exception as exc:
print('%r generated an exception: %s' % (endpoint, exc))
return results
if __name__ == '__main__':
for n in site_chunk:
start = time()
results = main(endpoints[0:n])
end = time()
print(f"{n} endpoints took {end-start:.2f} seconds")
The results are slightly better, and it's more economical for the operating system.
$ python socket_futures.py
10 endpoints took 0.83 seconds
100 endpoints took 6.06 seconds
500 endpoints took 34.15 seconds
1000 endpoints took 75.72 seconds
AsyncIO
We can rely on AsyncIO, so it's the software itself that leverages the asynchronous operations instead of the operating system scheduler.
Since requests library is not async, we can use aiohttp instead.
import asyncio
import aiohttp
async def get_url(session, domain_name):
results = {}
try:
async with session.get(f"https://www.{domain_name}", allow_redirects=False) as response:
await response.read()
results[domain_name] = response.status
except asyncio.exceptions.TimeoutError:
results[domain_name] = "timeout"
except aiohttp.ClientError:
results[domain_name] = "clienterror"
return results
async def main(endpoints):
timeout_seconds = 3
timeout = aiohttp.ClientTimeout(total=None, sock_connect=timeout_seconds, sock_read=timeout_seconds)
async with aiohttp.ClientSession(timeout=timeout) as session:
results = await asyncio.gather(*[get_url(session, endpoint) for endpoint in endpoints])
return results
if __name__ == '__main__':
for n in site_chunk:
start = time()
loop = asyncio.get_event_loop()
results = loop.run_until_complete(main(endpoints[0:n]))
end = time()
print(f"{n} endpoints took {end-start:.2f} seconds")
$ python socket_asyncio.py
10 endpoints took 1.46 seconds
100 endpoints took 3.15 seconds
500 endpoints took 16.91 seconds
1000 endpoints took 57.64 seconds
Final thoughts
If we compare the results altogether, we see a big difference from our first original design.
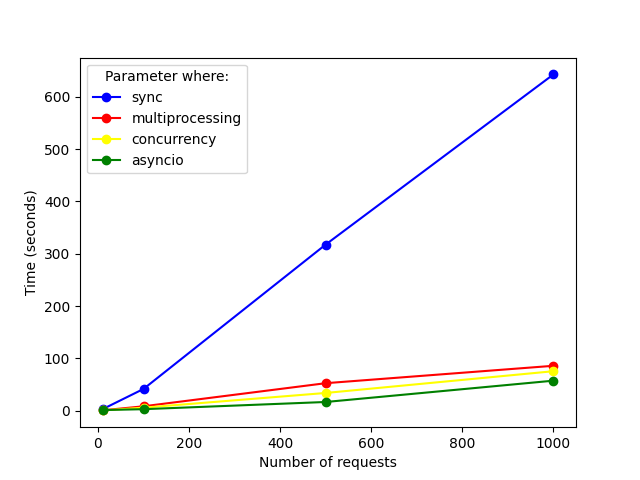
Skipping the synchronous approach and having a closer look to the rest.
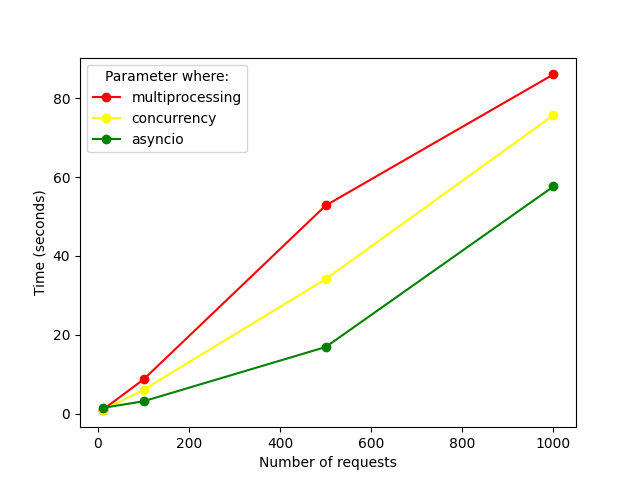
We saw that for this particular case, asyncio is a better solution. Although it took us a few patterns to end up with the fastest
solution, we realized that our original code changed quite a bit by including new libraries. In turn, those will change our tests too.
Coming back to the original questions, requests would work just fine, but we will create toil and at the same time, our
project will keep growing. At some point, we should allocate time to refactor it by adding new features.
Is this a bad thing? Not necessarily. Project requirements and staff are part of a business' living cycle.
While we could have already anticipated this with a good initial design, we might be refactoring it again down the line.
All the code can be found in this repository.